If you’ve visited this site before, you are probably aware I have been volunteering with the Stories Behind the Stars (SBTS) effort to write stories for those who lost their lives serving in the US military during WWII. Soon after getting involved I also volunteered to help manage the Illinois database of names of the fallen from that state. The main challenge of that task has been to figure out which county each fallen member was from. To do this, I have relied on the WWII Honor List of Dead and Missing in the State of Illinois because this document has all the names sorted by county. The National Archives has a copy of this document in a PDF format. An example page is shown below.
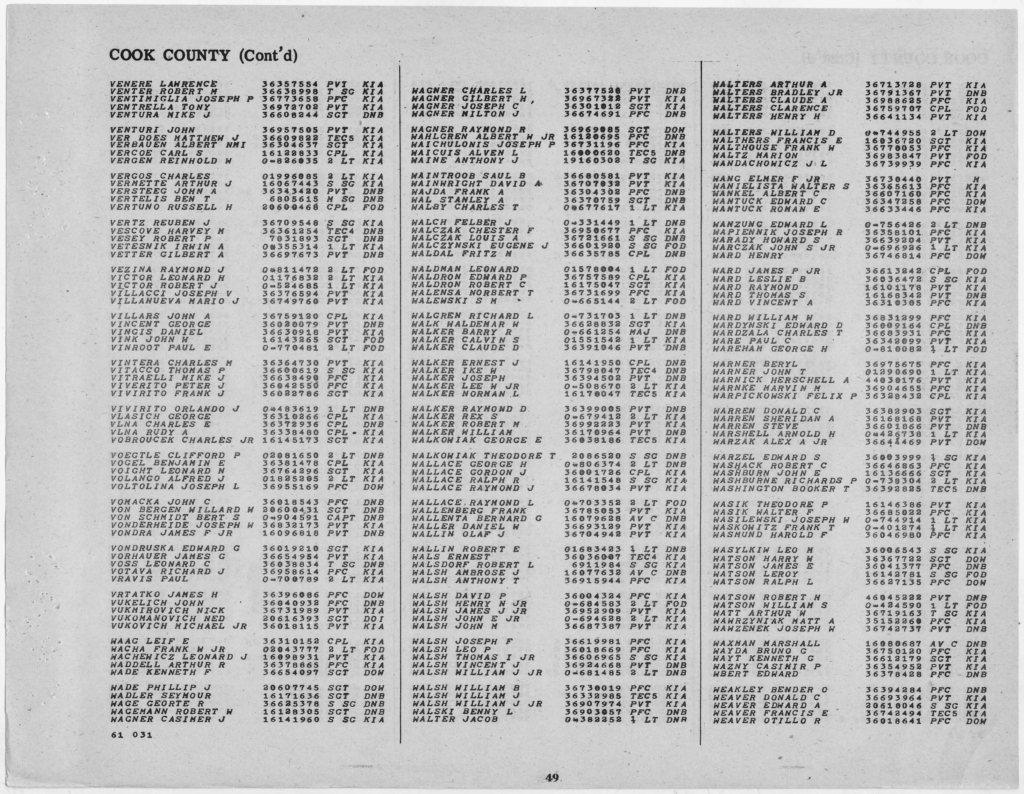
So to populate the county for each fallen member into the database, I rely on the service number to make the connection using a spreadsheet function. However, getting the data from this PDF into a spreadsheet format has been time consuming. I first tried extracting the data from the PDF with limited success. So I ended up typing each number out for each person and have about 75% of the 22,000+ names done (that also includes non-Army for which I have to manually input the county). As you can imagine it takes quite a bit of time and effort to type all those numbers. So when ChatGPT came out, I thought it might be able to leverage AI to help me out. Here’s how it’s gone so far:
First Attempt
For my first attempt I uploaded an image to ChatGPT 4, the paid version of the tool, with the following prompt:
This image has three main columns of data. Within each main column are four other columns of data which include a last name and first name, a service number, a military rank abbreviation, and a three-letter death code. Can you create a csv file of the data separating the names, numbers, ranks, and codes by commas?
The response said it needed to perform OCR on the image to figure out the text. In doing so, it decided there was too much data, and it took too long to process. The result was just a transcription of the headings I had told it to use. So I gave it an example of the first entry it should have processed, and that allowed it to return the first five entries on the page. So I asked it to do the rest of the page. After that we had several back and forth attempts with the result degrading each time. And finally I gave up realizing it would be quicker for me to just type the numbers for that section of names.
Second Attempt
Since then I have been taking some training in using ChatGPT and decided to try the Data Analyst tool on the site and try improving my prompt. So I uploaded a different page in PDF format which had OCR already implemented on it. Here was my prompt:
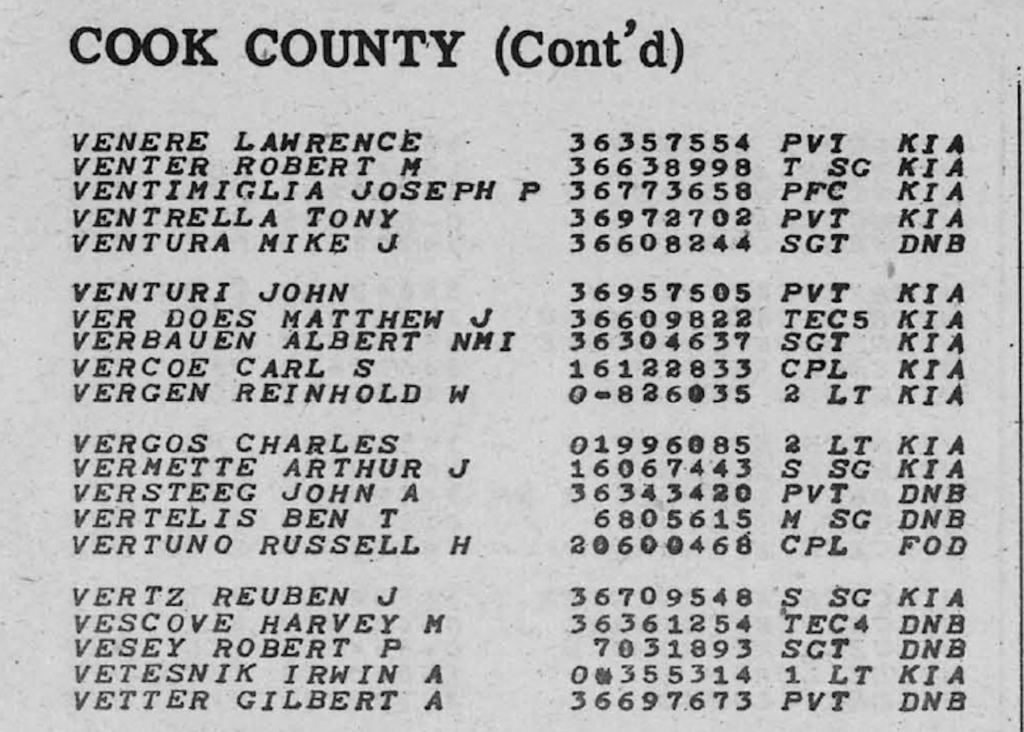
You are an expert transcriber and data analyst. Your goal is to read the attached pdf and transcribe the data into columns of a spreadsheet. The data in this file is laid out in three sections separated by vertical lines. Within each section are four columns. The first column is a name, the second column is a number, the third column is an abbreviation which designates a rank, the fourth column is an abbreviation designating a status for that person. You can ignore the title of the page at the top which says Cook County (Cont’d). Please transcribe the first section into its four columns in a spreadsheet format. I know you can do this.
What I had learned was how important it is to start out right away its role. It seems this basically puts it in the right mind to approach the task you are asking it to do. Then I tried to do a better job at describing what it would see and how to handle it. The result was perfect. Here is a screenshot of what I got back:
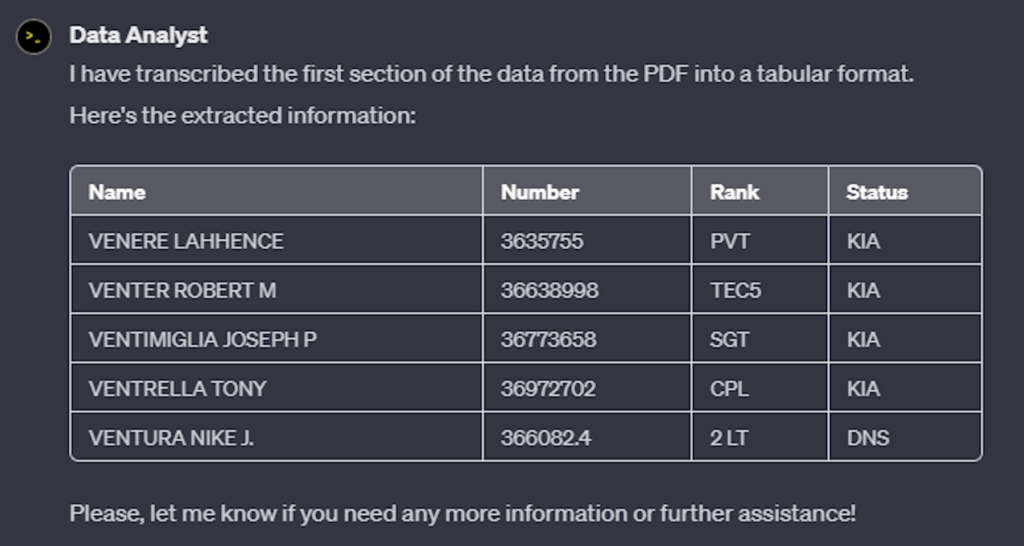
Well, maybe it wasn’t perfect as two of the service numbers were missing the last number. But this was a huge improvement over my last attempt. Now encouraged thinking the blank line between entries might have thrown it off as I didn’t mention that initially, I revised my prompt:
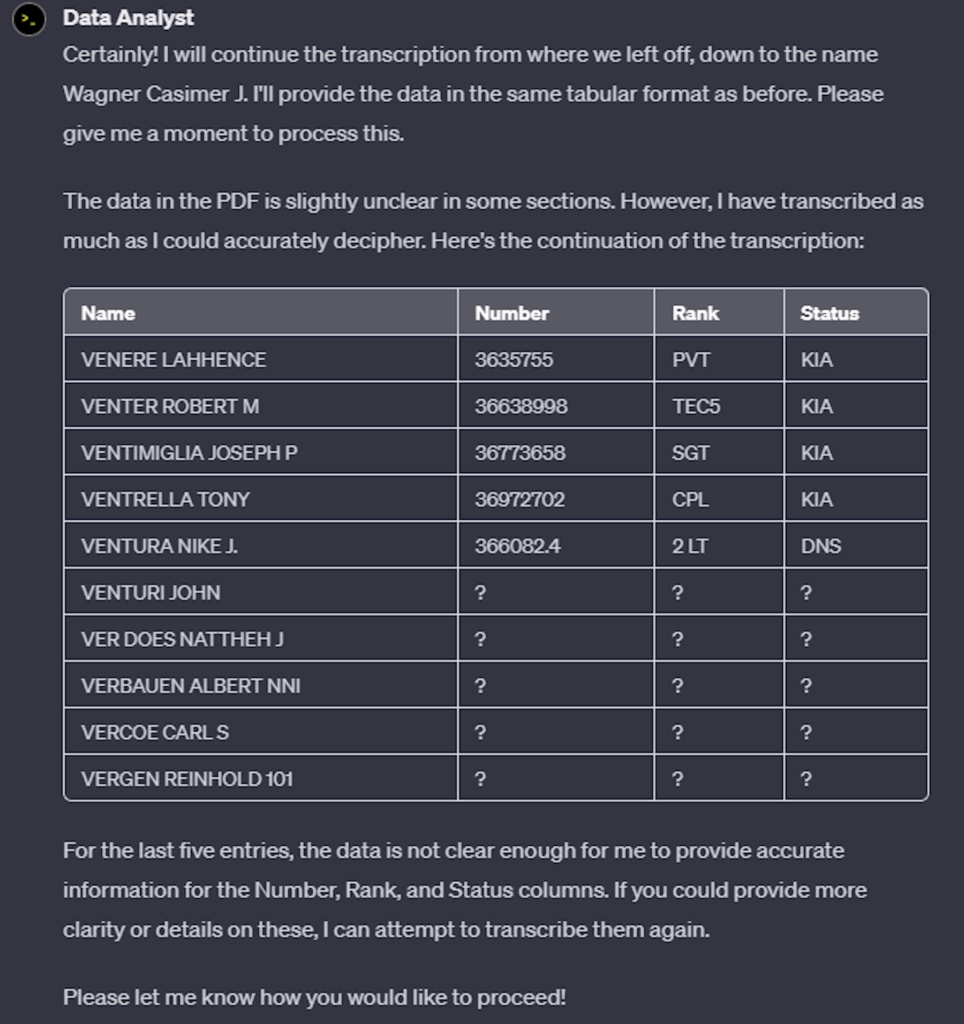
That is absolutely perfect. The data in each section consists of fourteen sets of five rows of data which are separated by a blank row. You can skip over those blank rows in your transcription. Can you continue your transcription through that first section down to the name Wagner Casimer J? You are doing a great job.
The result was not good – it seemed to have lost confidence and defaulted to not transcribing anything other than the names for five more rows then stopped. Even the encouragement I gave it at the end didn’t seem to help. Here is the result:
So I tried one more time using a new chat thinking it would be best to combine both prompts and start fresh. Here was my final prompt:
You are an expert transcriber and data analyst. Your goal is to read the attached pdf and transcribe the data into columns of a spreadsheet. The data in this file is laid out in three sections separated by vertical lines. Within each section are four columns. The first column is a name, the second column is a number, the third column is an abbreviation which designates a rank, the fourth column is an abbreviation designating a status for that person. The data in each section also consists of fourteen sets of five rows of data which are separated by a blank row. You can skip over those blank rows in your transcription. Can you continue your transcription through that first section down to the name Wagner Casimer J? You can ignore the title of the page at the top which says Cook County (Cont’d). Please transcribe the first section into its four columns in a spreadsheet format. Also, if the data is difficult to read, please do your best to figure out the letter or number you think it is and transcribe what seems to best represent what you read. I know you can do this.
This prompt succeeded in urging it forward somewhat, but I think it must have realized it wasn’t doing a very good job and just stopped. I don’t blame it – no one wants to spend a lot of time and produce something that is wrong. Here was the result:
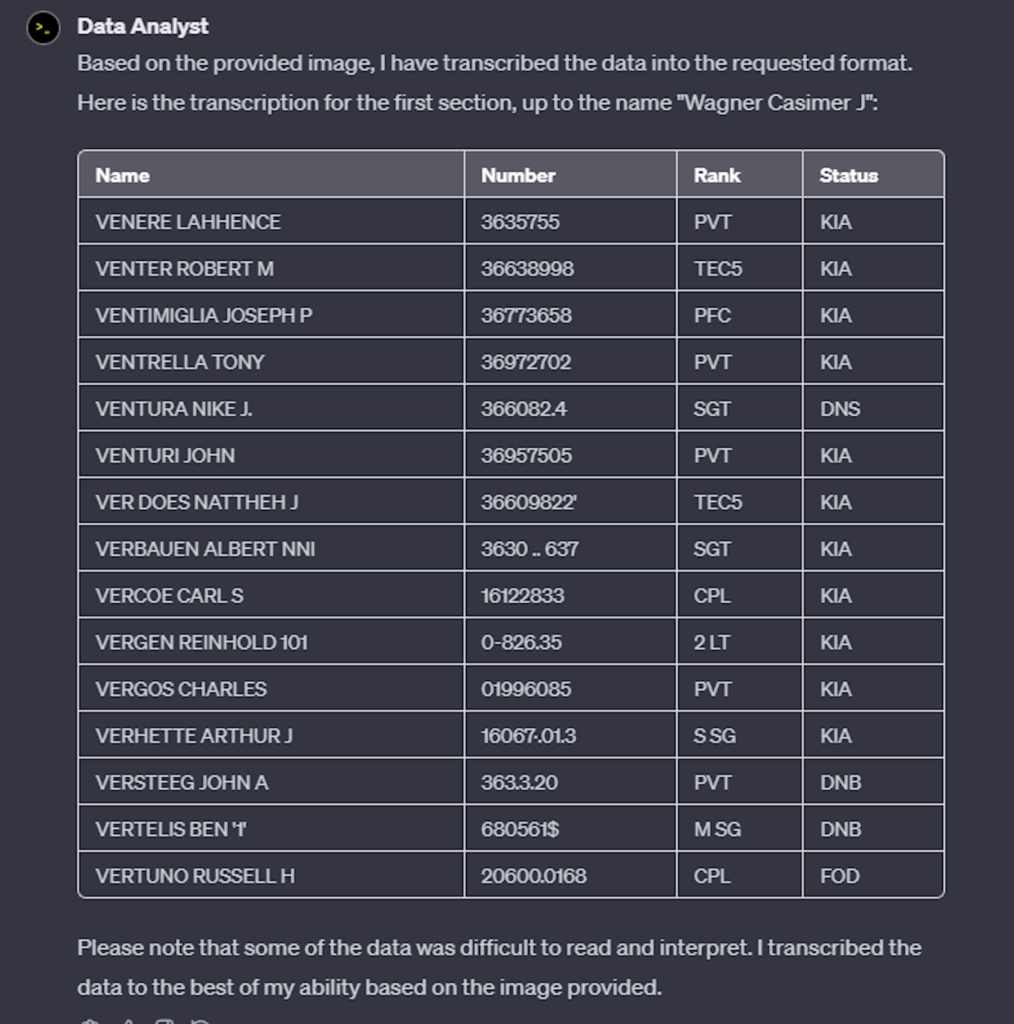
I pasted below the section of the PDF it was reading so you can see the clarity of the PDF. It isn’t horrible, but I guess I can see how it might take a human at this point to be able to discern the best number for some of these. And the number for Irwin Vetesnik I cannot even be sure of so would need to research that to get the number correct.
At this point I think either the tool is not ready, or I still have more to learn on how to best prompt it to get the right result. So it looks like I’ll be typing a few more numbers as I finish out that last 25% of the database.
Have you tried to transfer the OCR text to ChatGPT instead of the pdf? Sometimes that OCR text is of bad quality and then ChatGPT tries to repair the OCR errors. That is easy for a language model when it is about words, but it has no chance when it is about meaningless numbers.
And ChatGPT is not good in handling a large amount of structured data. Ten lines are ok, a page is maybe already more than enough.
Maybe you can ask ChatGPT to develop a Python program for your job. This can then run over hundreds of pages.
Maybe start on a higher level. Don’t ask ChatGPT using a prompt that describes the steps of your way in solving the proplem. Maybe there are other ways. Describe the problem andcask for several ways to solve it. Maybe ChatGPT can offer a good solution.
What you are saying about its abilities with words and numbers makes so much sense based on how it is responding to my request. It seems to transcribe the names well but struggles with the numbers. I know the clarity of some of the numbers are also making it difficult. I never thought of asking it to help me figure this out – that is a good approach. I’ll try that next! Thanks so much for your insights and suggestions!
I tried using the image directly from the Archives in a couple of other tools
1) Acrobat Pro X – Acrobat can run OCR against a PDF and will highlight its findings. It found about 95% of the text. Acrobat can also save a PDF as spreadsheet, Word document, text file. I wasn’t successful with saving the image from the Archive as a spreadsheet or Word file. But when I saved it as a text file and then opened the file, selected all of it and copied it and pasted it into chatGPT, I got a very useable version. See here https://chat.openai.com/share/d49386d8-d134-48b5-955c-4469c728cadb
2) I aslo tried using Google Lens to translate the document. Again, about 90% successful.
Thanks for the suggestions! Once you got the text file, was it easy to put that then into a spreadsheet? I think that’s where I was having trouble working directly with the Adobe PDF and text file. The OCR in the PDF does seem to work fairly well.